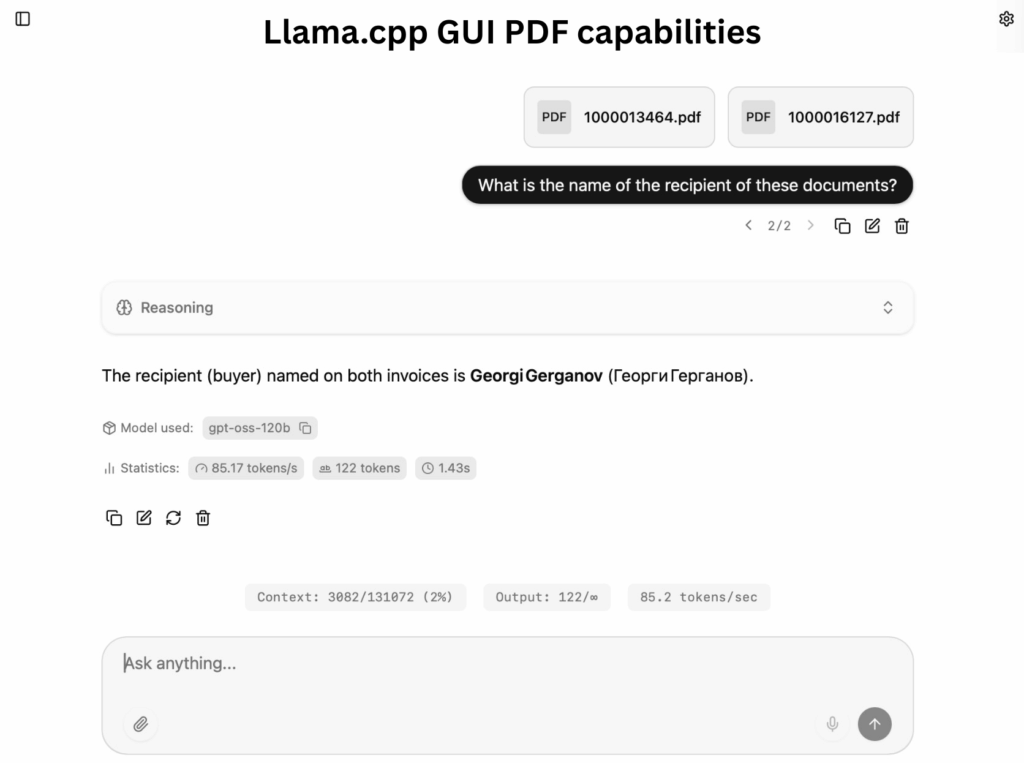
Llama.cpp suporta uma ampla gama de arquiteturas de modelos que incluem Llama 1, 2 e 3, Mistral, Phi, Gemma, Yi, DeepSeek, Qwen, Solar, Alpaca e StableLM. llama.cpp possui integração nativa com CUDA, ROCm da AMD, Vulkan, Opencl e SYCL para inferência acelerada. O software suporta GPUs Nvidia (CUDA), GPUs AMD (ROCm), Apple Silicon (Metal) e outras GPUs compatíveis com Vulkan. O sistema k-quants (Q4_K_M, Q5_K_S, Q6_K e assim por diante) incorpora quantização por bloco que também ajuda a preservar a qualidade do modelo enquanto reduz drasticamente o consumo de memória. Llama.cpp inclui scripts Python para converter modelos de vários formatos (PyTorch, SafeTensors) para GGUF.
Fonte: https://llama-cpp.com/