Instale e verifique o exllamav2 (recomendado):
(Opcional) Instale o llama cpp-python:
(Opcional) Instale a atenção do flash para melhorar o desempenho:
(Opcional) Instale llama.cpp:
Instale Gallama:
Ou instale a partir da fonte:
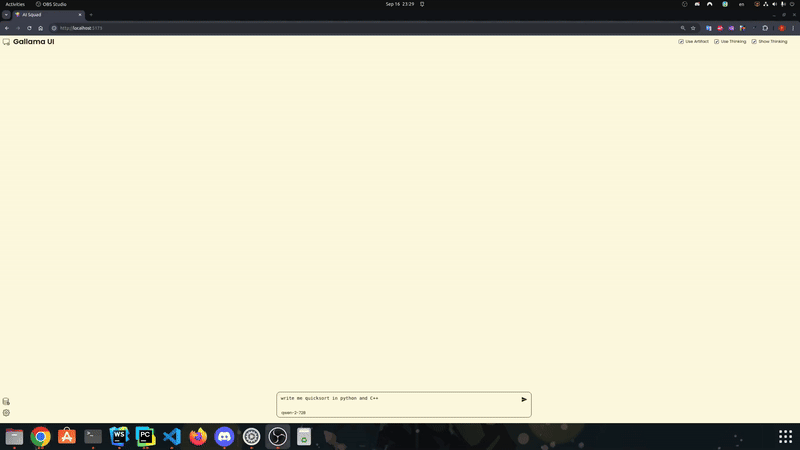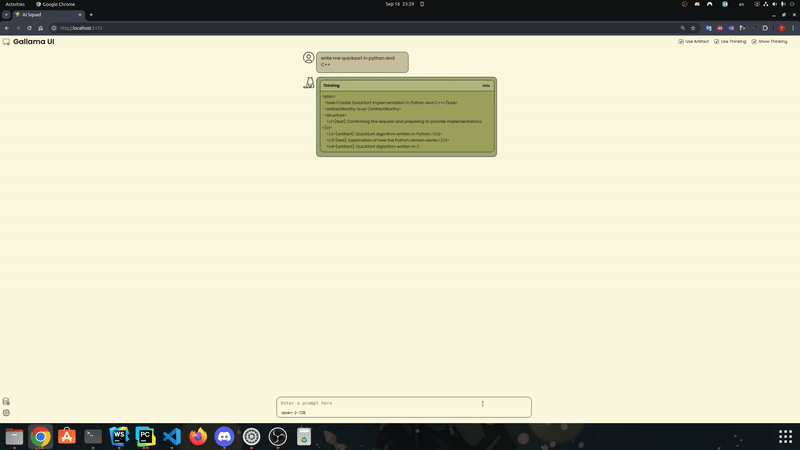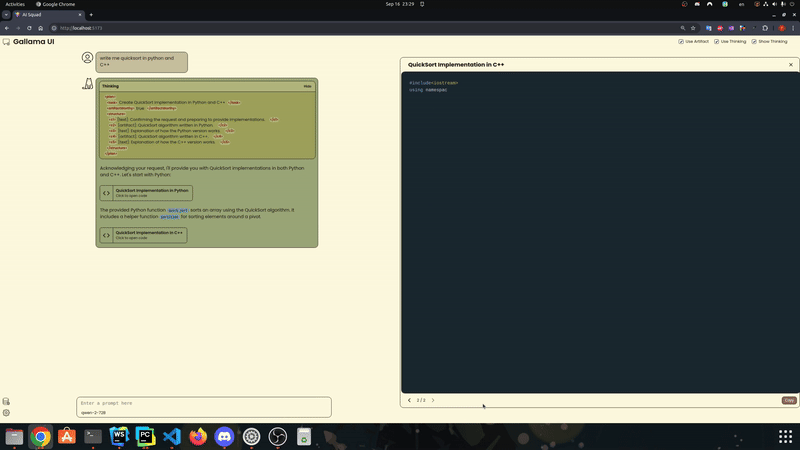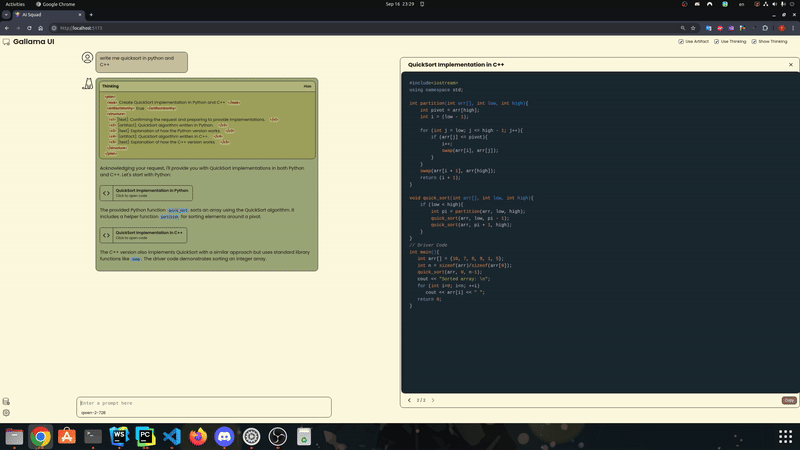
Siga estas etapas para usar o modelo.Ele tenta fechar a lacuna entre o mecanismo de inferência pura (como exllamav2 e llama.cpp) e necessidades adicionais de trabalho agêntico (por exemplo, chamada de função, restrições de formatação).Inicie um modelo com tamanho e quantização reduzidos de cache:
Para o modelo com alto contexto, menor o comprimento da sequência pode reduzir significativamente o uso de VRAM.Para Pixtral, instale o exllama v2 v0.2.4 em diante
Para o Exllama V2, instale o Dev Branch do Exllama V2, pois o código ainda não está fundido na v0.2.4.Para poder usar o modo de artefato de maneira eficaz, você precisará de um modelo suficientemente bom, a partir de nossos testes, precisará de 22b minimamente codestral.