Para garantir a máxima reprodutibilidade, considere a criação de um novo ambiente do CONDA:
O LLMTune também requer uma GPU da NVIDIA (Pascal Architecture ou mais recente);Outras plataformas não são suportadas atualmente.Seus recursos incluem:
Um benefício de poder finalizar o LLMS maior (por exemplo, parâmetros 65b) em uma GPU é a capacidade de aproveitar facilmente o paralelismo de dados para modelos grandes.Isso gera texto do modelo básico:
Mais interessante, podemos gerar saída a partir de um modelo de instrução-finetuned, fornecendo também um caminho para os pesos do adaptador LORA.Debaixo do capô, o LLMtune implementa o algoritmo Lora sobre um LLM compactado usando o algoritmo GPTQ, que requer a implementação de um passe para trás para o LLM quantizado.Seus objetivos são:
Este é o modelo LLMTune com uma instrução Finetuned Llama-65b Model em um NVIDIA A6000:
Este exemplo é baseado em um prompt de demonstração da ALPACA.
Trending posts dos últimos 30 dias
-

-
-

Mantenedor do Curl: os relatórios de segurança de IA não são mais desleixados
16 de maio de 2026| 0 Comments -
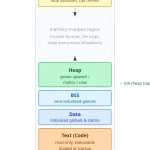
Memória virtual explicada como um diálogo entre um processo e o kernel Linux
16 de maio de 2026| 0 Comments -

Migração de código auxiliada por IA: o Google obteve uma migração 6x mais rápida do TensorFlow para Jax
14 de maio de 2026| 0 Comments